Vulkan Video is Open: Application showcase !
From
dabrain34
by
Stéphane Cerveau

UK calling
Long time no see this beautiful grey sky, roast beef on sunday and large but full packed pub when there is a football or a rugby game (The rose team has been lucky this year, grrr).
It was a delightful journey in the UK starting with my family visiting London including a lot (yes a lot…) of sightviews in a very short amount of time. But we managed to fit everything in. We saw the changing of the guards, the Thames river tide on a boat, Harry Potter gift shops and the beautiful Arsenal stadium with its legendary pitch, one of the best of England.
It was our last attraction in London and now it was time for my family to go to Standsted back home and me to Cambridge and its legendary university.
To start the journey in Cambridge, first I got some rest on Monday in the hotel to face the hail of information I will get during the conference. This year, Vulkanised took place on Arm’s campus, who kindly hosted the event, providing everything we needed to feel at home and comfortable.
The first day, we started with an introduction from Ralph Potter, the Vulkan Working Group Chair at Khronos, who introduced the new 1.4 release and all the extensions coming along including “Vulkan Video”. Then we could start this conference with my favorite topic, decoding video content with Vulkan Video. And the game was on! There was a presentation every 30 minutes including a neat one from my colleague at Igalia Ricardo Garcia about Device-Generated Commands in Vulkan and a break every 3 presentations. It took a lot of mental energy to keep up with all the topics as each presentation was more interesting than the last. During the break, we had time to relax with good coffee, delicious cookies, and nice conversations.
The first day ended up with a tooling demonstrations from LunarG, helping us all to understand and tame the Vulkan beast. The beast is ours now!
As I was not in the best shape due to a bug I caught on Sunday, I decided to play it safe and went to the hotel just after a nice indian meal. I had to prepare myself for the next day, where I would present “Vulkan Video is Open: Application Showcase”.
Vulkan Video is Open: Application showcase !
First Srinath Kumarapuram from Nvidia gave a presentation about the new extensions made available during 2024 by the Vulkan Video TSG.
It started with a brief timeline of the video extensions from the initial h26x decoding to the latest VP9 decode coming this year including the 2024 extensions such as the AV1 codec.
Then he presented more specific extensions such as VK_KHR_video_encode_quantization_map, VK_KHR_video_maintenance2 released during 2024 and coming in 2025, VK_KHR_video_encode_intra_refresh.
He mentioned that the Vulkan toolbox now completely supports Vulkan Video, including the Validation Layers, Vulkan Profiles, vulkaninfo or GFXReconstruct.
After some deserved applause for a neat presentation, it was my time to be on stage.
During this presentation I focused on the Open source ecosystem around Vulkan Video. Indeed Vulkan Video ships with a sample app which is totally open along with the regular Conformance Test Suite. But that’s not all! Two major frameworks now ship with Vulkan Video support: GStreamer and FFmpeg.
Before this, I started by talking about Mesa, the open graphics library. This library which is totally open provides drivers which support Vulkan Video extensions and allow applications to run Vulkan Video decode or encode.
The 3 major chip vendors are now supported. It started in 2022 with RADV, a userspace driver that implements the Vulkan API on most modern AMD GPUs. This driver supports all the vulkan video extensions except the lastest ones such as VK_KHR_video_encode_quantization_map or VK_KHR_video_maintenance2 but this they should be implemented sometime in 2025. Intel GPUs are now supported with the ANV driver, this driver also supports the common video extensions such as h264/5 and AV1 codec. The last driver to gain support was at the end of 2024
where several of the Vulkan Video extensions were introduced to NVK, a Vulkan driver for NVIDIA GPUs. This driver is still experimental but it’s possible to decode H264 and H265 content as well as its proprietary version. This completes the offering of the main GPUs on the market.
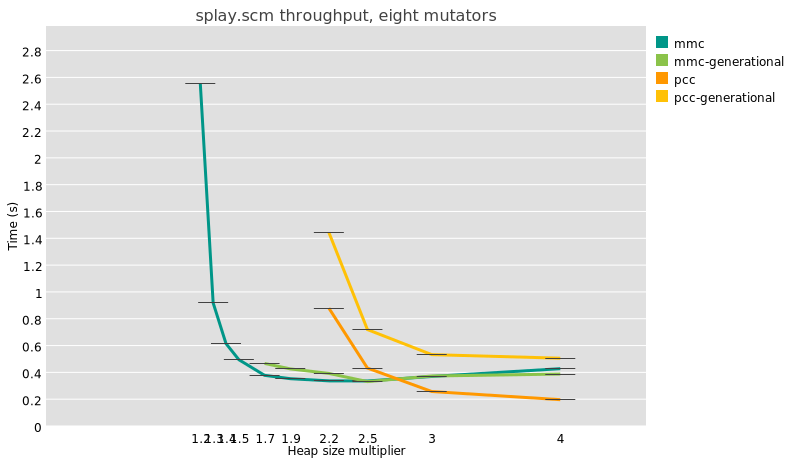
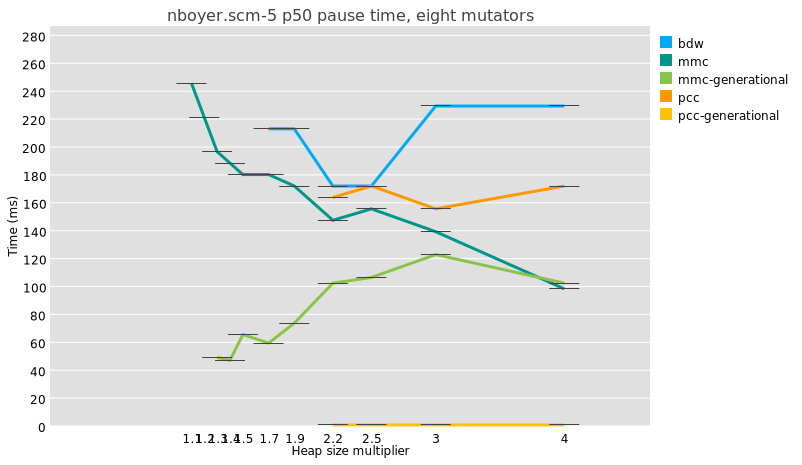
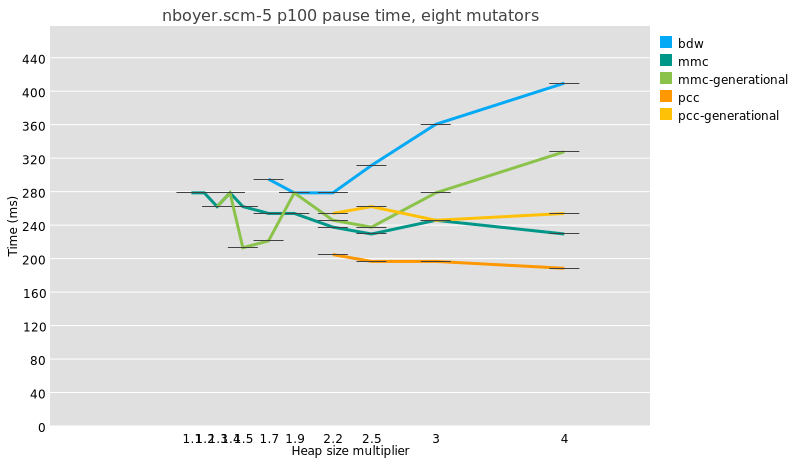
Then I moved to the applications including GStreamer, FFmpeg and Vulkan-Video-Samples. In addition to the extensions supported in 2025, we talked mainly about the decode conformance using Fluster. To compare all the implementations, including the driver, the version and the framework, a spreadsheet can be found here.
In this spreadsheet we summarize the 3 supported codecs (H264, H265 and AV1) with their associated test suites and compare their implemententations using Vulkan Video (or not, see results
for VAAPI with GStreamer).
GStreamer, my favorite playground, can now decode H264 and H265 since 1.24 and recently got the support for AV1 but the merge request is still under review. It supports more than 80% of the H264 test vectors for the JVT-AVC_V1 and
85% of the H265 test vectors in JCT-VC-HEVC_V1.
FFMpeg is offering better figures passing 90% of the tests. It supports all the avaliable codecs including all of the encoders as well.
And finally Vulkan-Video-Samples is the app that you want to use to support all codecs for both encode and decode, but its currently missing support for mesa drivers when it comes to use Fluster decode tests..
Vulkanised on the 3rd day
During the 3rd day, we had interesting talks as well demonstrating the power of Vulkan, from Blender, a free and open-source 3D computer graphics software tool switching progressively to Vulkan, to the implementation of 3D a game engine using Rust, or compute shaders in Astronomy. My other colleague at Igalia, Lucas Fryzek, also had a presentation on Mesa with Lavapipe: a Mesa’s Software Renderer for Vulkan which allows you to have a hardware free implementation of Vulkan and to validate extensions in a simpler way. Finally, we finished this prolific and dense conference with Android and its close collaboration with Vulkan.
If you are interested in 3D graphics, I encourage you to attend future Vulkanised editions, which are full of passionate people. And if you can not attend you can still watch the presentation online.
If you are interested in the Vulkan Video presentation I gave, you can catch up the video here:
Or follow our Igalia live blog post on Vulkan Video:
https://blogs.igalia.com/vjaquez/vulkan-video-status/
As usual, if you would like to learn more about Vulkan, GStreamer or any other open multimedia framework, please feel free to contact us!





























{kind=link}
{kind=link}